Ola Sanusi, PhD

Educator | Data Scientist | Researcher
View My LinkedIn Profile
| Fake News Detection using Machine Learning Classifiers | Natural Language Processing (NLP) Author: Ola Sanusi, PhD |
Background
Fake news has been dominating social and online news media in recent years. Fake news can be considered as unverified, inaccurate, and maliciously distorted information that are not easy to distinguish from genuine news (Jang, Park, & Seo, 2019). I can conclude that fake news are news content that have been verified to be false by fact checkers. However, there are no agreed upon definition of the term fake news. One thing that can be generally be agreed upon is that fake news encapsulate pieces of information that are generally false, hoaxes, misleading or exaggerated. A conceptual framework created by Wardle and Derakhsan (2017) can help us better understand fake news. This conceptual model presented in figure 1 fake news into 3: (1) mis-information (2) dis-information (3) mal-information.
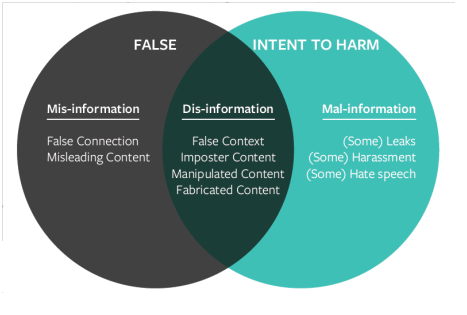
Figure 1: Conceptual framework explaining fake news. Source: Wardle and Derakhsan (2017)
Fake news weakens the legitimacy of media institutions because the false information disseminated by fake news spread faster and deeper consequently reaching larger audience(Bozarth & Budak, 2020). The coverage and spread of false information is alarming. For example, during the 2016 U.S election campaign, the top 20 discussed fake election information generated about 8 million reactions, shares and comments on Facebook while on the other hand, genuine/real news from the larger news websites garner about 7.3 million comments, reactions and shares (Zhou, Jain, Phoha, & Zafarani, 2020). It is therefore imperative that fake news is detected in its earlier phase before it reaches a broad audience since is it now extremely difficult for the general public to distinguish fake news from credible/genuine/real news (Bozarth & Budak, 2020).
Problem Statement
Due to the explosion of fake news and the fact that fake news reaches more audience than real/genuine news. It is very important that there is a way to quickly identify which news is fake or real so that they can be removed immediately in order to reduce the number of people it reach. We should be able to use machine learning algorithms to study word patterns in fake and real news to be able to distinguish which news is fake or real.
Preparing the Dataset
The dataset used was obtained from Fake News Corpus on GitHub. The Corpus (27 GB) contains zipped dataset of news articles with about 8.5 million instances, a total of 17 feature columns and 11 categories in the label column. This Corpus was previously used in my Georgetown University Data Science Capstone project. Due to the size of the dataset and limitation of PC, initial data preparation to get rid of unneeded columns and rows were performed on AWS Sagemaker studio with higher memory VMs. The notebook that contains all the steps performed to get data into a managable size that can be processed on my local PC is hosted on my GitHub.
Summary of the raw and subset datasets
| Raw Dataset (Fake News Corpus) | Subset Dataset (FakeNews2Mil) | |
|---|---|---|
| Domains | 673 | 438 |
| Fake News Domains | 107(15.9%) | 305(69.6%) |
| Fake News Articles | 894,481(10.5%) | 999,396 (50.0%)* |
| Number of features | 17 | 4 |
| Classes in label | 11 | 2 |
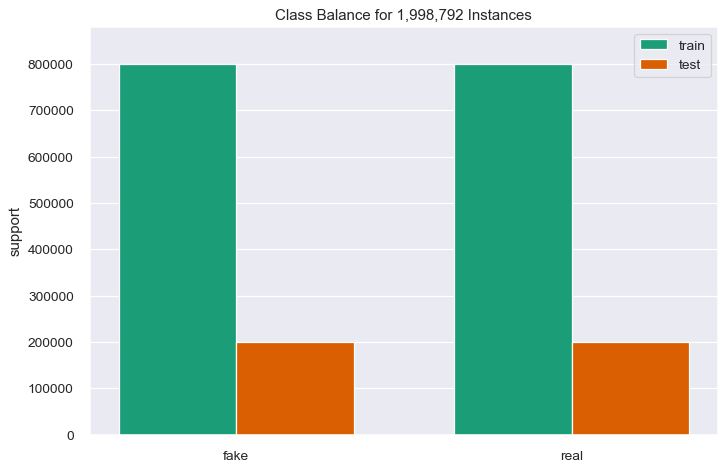
| Total Number of articles | 8,529,000 | 1,998,752 |
| File size (GB) | 27 | 5 |
*Classes were combined and recoded to have a binary class (fake and real)
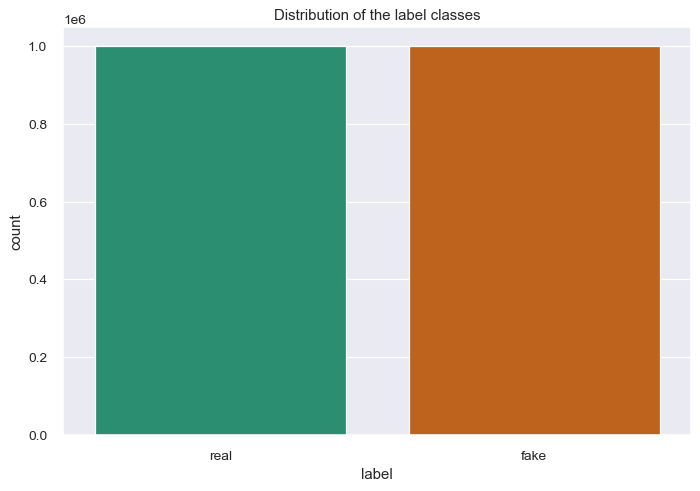
The subset dataset used for this project contains of approximately 2 million instances, binary class (fake and real) in the target variable.
The dataset
df.head(3)
| domain | title | content | label | |
|---|---|---|---|---|
| 0 | dailykos | More and more British election talk | Because it’s the big story of the night.\n\nUp… | real |
| 1 | christianpost | Brian Williams and the Tyranny of Ego | Expand | Collapse Not available David French, … | real |
| 2 | nakedcapitalism | Comments on: How American Corporations Transfo… | The Bible has an interesting (no pun intended)… | real |
df.info(memory_usage='deep')
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1998792 entries, 0 to 1998791
Data columns (total 4 columns):
# Column Dtype
--- ------ -----
0 domain category
1 title object
2 content object
3 label object
dtypes: category(1), object(3)
memory usage: 10.2 GB
Distribution of label classes
Data Cleaning and Text Preprocessing
The corpus need to be cleaned in order to get rid of noises such as accented characters, punctuations, stopwords etc. before it can be used for model training and predictions. The following preprocessing steps are completed to clean the corpus:
- noise removal
- creation of additional features ( word and character counts, average word length)
- feature engineering by splitting Data into Trainning and Test
- feature vectorization using column transformer and Tfidfvectorizer
- sparse feature matrix normalization
Features considered excluded the domain column because of the imbalance in the distribution of domain by label classes and from the result of my Georgeotown capstone group project that suggested that the domain is responsible for the overfitting of all the models. According to the results from the Georgetown University Data Science Capstone project, the classifiers seems to be learning domain-specific features as opposed to the actual word patterns that distinguish fake news from real news articles
Models training and evaluations
12 different ML classifiers were used in this project.
Several machine learning classifiers was used in model training and prediction. These classifiers belong to individual algorithms, ensemble algorithms and neural network algorithms.
- Individual algorithms
- Logistic Regression
- Linear SVC
- Multinomial Naive Bayes
- Decision Tree
- Stochastic Gradient Descent Classifier
- Ensemble Algorithms
- Random Forest
- Extra Trees
- Adaboost
- LightGBM
- XGBoost
- Neural Network Algorithms
- Multiple Layer Perceptron Classifier
- Deep Neural Network
model selection
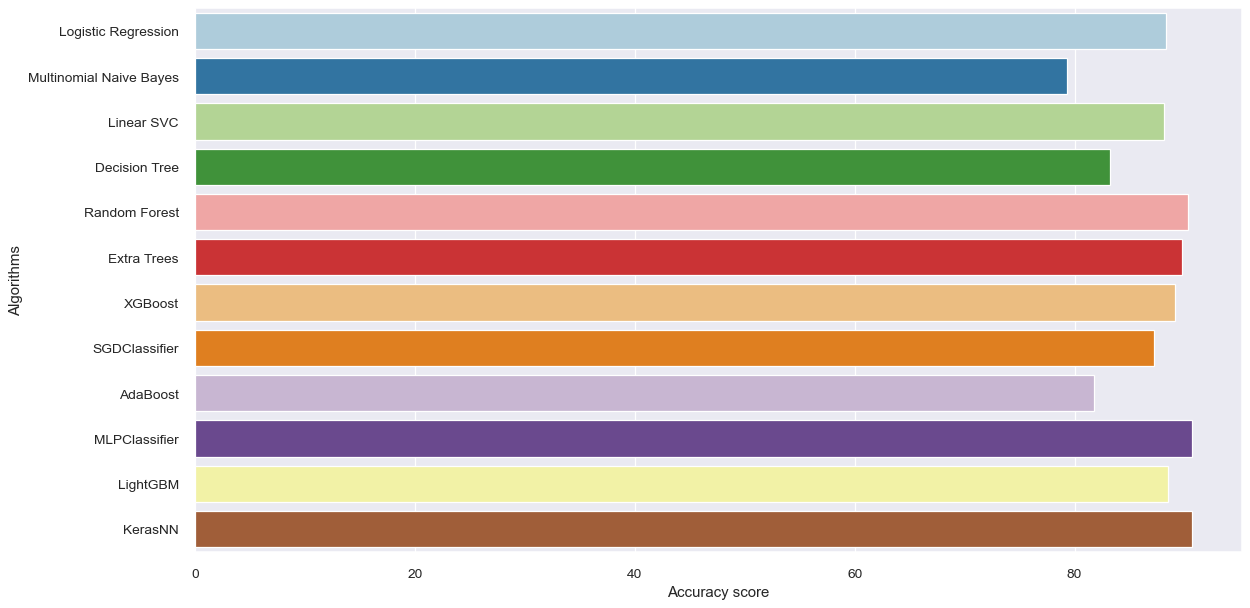
| Algorithms | Accuracy Score (%) | Recall(%) | True Positive(TP) |
|---|---|---|---|
| Individual | |||
| - Logistics Regression | 88.26 | 89.00 | 177,749 |
| - Multinomial NB | 79.33 | 95.00 | 189,776 |
| - Linear SVC | 88.16 | 89.50 | 178,664 |
| - SGDClassifier | 87.25 | 90.00 | 178,655 |
| - Decision Tree | 83.22 | 75.90 | 151,599 |
| Ensemble | |||
| - Random Forest | 90.33 | 92.50 | 184,616 |
| - Extra Trees | 89.82 | 93.20 | 186,067 |
| - Adaboost | 81.79 | 85.30 | 170,201 |
| - XGBoost | 89.14 | 89.30 | 178,351 |
| - LightGBM | 88.55 | 88.90 | 177,371 |
| Neural Network | |||
| - MLP Classifier | 90.66 | 90.80 | 181,333 |
| - Deep NN (Keras) | 90.66 | 91.00 | 182,362 |
Conclusions
Among all the classifiers used in this project, the neural network algorithims (MLP classifier and Deep NN) has the best performance when the accuracy score was used a the primary model evaluation criteria. However, when recall of the fake class is considered, multinomial NB performed the best because it was able to correctly predict the highest number of the fake news articles.
On the other hand, if all performance evaluation criteria are considered, the deep neural network with three hidden layers is the best machine learning classifier that best predict and distinguishes fake news from real news articles.
With the highest classification accuracy score of 90.66%, recall of 91%, the Deep NN classifier is perfect for distinguishing word patterns in fake news articles.
Check out full codes and notebook on github
References
Bozarth, L., & Budak, C. (2020). Toward a Better Performance Evaluation Framework for Fake News Classification. Paper presented at the Proceedings of the International AAAI Conference on Web and Social Media.
Jang, Y., Park, C.-H., & Seo, Y.-S. (2019). Fake news analysis modeling using quote retweet. Electronics, 8(12), 1377.
Wardle, C., & Derakhshan, H. (2017). Information disorder: Toward an interdisciplinary framework for research and policy making. Council of Europe report, 27, 1-107
Zhou, X., Jain, A., Phoha, V. V., & Zafarani, R. (2020). Fake news early detection: A theory-driven model. Digital Threats: Research and Practice, 1(2), 1-25.
Acknowledgements
A big thanks to my capstone project team members (Drew207, elceespatial, j-tanner, deescaramella, ajohns75) during my data science certificate program at Georgetown University. Working with you guys on the Fake News NLP project was a very remarkable learning experience.